Se si prende in esame un qualunque sistema di archiviazione, troveremo che i dati vengono registrati su supporti fisici in grado di conservare le informazioni nel tempo e che, per facilitare le operazioni più comuni come la ricerca, la modifica e la loro consultazione, essi vengono strutturati in opportuni formati e convenientemente organizzati. Questo è vero indipendentemente dal tipo di sistema di archiviazione considerato, manuale oppure automatico. Però, forse, per sottolineare meglio l’importanza dei concetti di persistenza dei dati e di organizzazione dell’archivio intesa come una condizione indispensabile per garantire un efficiente ritrovamento dei dati, diventa più facile ed intuitivo farlo prendendo in considerazione il caso di un sistema manuale. In un sistema manuale di solito i dati sono registrati fisicamente su supporti cartacei che, come può suggerirci la figura di sotto, possono essere organizzati in fogli singoli, quaderni, registri ed ancora altre strutture, magari disposti all’interno di cartelle che a loro volta possono essere ordinate secondo opportuni criteri all’interno di cassetti, anch’essi organizzati secondo una certa logica. E’ abbastanza intuitivo capire che la particolare organizzazione che verrà adottata non solo sarà indispensabile per rendere più veloce il ritrovamento dei dati, ma sarà anche funzionale alla gestione dei dati che deve essere realizzata.

Nel caso di un sistema automatico quello che cambia è il supporto fisico, che è rappresentato dalle memorie di massa con i suoi file, e il fatto che la gestione dell’archivio viene affidata ad un’elaboratore automatico, ma per quel che riguarda l’organizzazione dell’archivio valgono discorsi analoghi. Il modo in cui un’applicazione può utilizzare un archivio di dati e, quindi, le funzionalità che con l’applicazione il programmatore può implementare, dipendono dal modo con cui i dati vengono organizzati nell’archivio e, quindi, dalle scelte adottate nella progettazione dell’archivio. Un archivio ancor prima dei dati veri e propri in esso memorizzati, è il contenitore dei dati che va progettato e inevitabilmente il modo in cui viene strutturato ed organizzato determina sia quali sono le operazioni che le applicazioni potranno eseguire, sia l’efficienza con cui saranno eseguite. Questi concetti saranno evidenti quando in un altro articolo vedremo alcuni esempi di organizzazione degli archivi, prima di ciò però può essere utile mettere in risalto alcune caratteristiche molto comuni dei file di archivio.
In un file di archivio nel caso più tipico i dati vengono organizzati all’interno di una struttura che può essere visualizzata come una tabella che su ciascuna riga contiene una registrazione (in inglese, record). Nei casi meno banali, inoltre, un archivio può essere più convenientemente composto da più file, ciascuno contenente una tabella diversa. In tal caso le tabelle hanno la particolarità di non essere fra loro indipendenti, ma al contrario di essere “collegate”, nel senso che contengono dati correlati.
ESEMPIO. Si pensi al caso di un archivio in cui si debbano memorizzare le informazioni relative a delle vendite. Potrebbe essere conveniente organizzare i dati separando fra loro quelli dei clienti, dei prodotti e quelli che riguardano più propriamente ciascuna vendita. Si faccia attenzione al fatto che per quanto i dati vengono separati in tabelle diverse, comunque risultano essere strettamente correlati fra loro, perché ciascuna vendita sempre dovrà riguardare almeno un cliente e dovrà coinvolgere uno o più prodotti. Pertanto se non si vuole determinare una perdita di informazione, queste correlazioni necessariamente nell’archivio devono essere mantenute.
CONCETTO DI METADATI. In generale, dunque, un archivio è costituito dall’insieme di più tabelle e dall’insieme delle correlazioni che legano fra loro i dati delle diverse strutture e che, si fa notare, si traducono sotto forma di altri dati che sono detti metadati per distinguerli dai dati veri e propri memorizzati nell’archivio. I metadati servono per definire l’organizzazione dell’archivio e nell’archivio si aggiungono ai dati veri e propri.
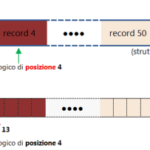
In un archivio informatico, perciò, nel caso più generale le informazioni vengono rappresentate con dati strutturati nel formato di record convenientemente organizzati all’interno di tabelle memorizzate su file e un archivio è costituito da uno o più file, ciascuno contenente una tabella che raccoglie dati omogenei e relativi ad una determinata entità. I dati sono omogenei nel senso che tutti i record inseriti in una tabella, pur contenendo dati diversi presentano gli stessi campi ossia hanno una stessa struttura logica che viene definita tracciato record. Esempi di entità sono quella dei clienti, quella dei prodotti e quella delle vendite individuate nell’esempio precedente.
Un file di un archivio di dati, in definitiva, può essere realizzato come un file strutturato (ossia, file di record) che può essere utilizzato dall’applicazione come una sequenza contigua di record che graficamente può essere rappresentata come una tabella in cui:
- ciascuna RIGA rappresenta il RECORD di una diversa registrazione;
- ciascuna COLONNA contiene dati che sono tutti di uno stesso tipo e rappresenta un CAMPO del tracciato record.