Dopo una breve introduzione all’organizzazione degli archivi (link articolo) e dopo aver accennato alle principali problematiche legate all’organizzazione degli archivi (link articolo), in quest’articolo vediamo quali sono i principali tipi di organizzazione degli archivi tradizionali.
Organizzazione sequenziale
L’organizzazione di un archivio più semplice da realizzare è quella sequenziale. L’organizzazione sequenziale, infatti, non prevede alcun meccanismo che permetta di risalire direttamente alla posizione di un record, pertanto non fornisce la possibilità di un accesso diretto ad un record specifico. L’accesso in LETTURA ad uno specifico record diventa possibile solo dopo una scansione dell’archivio, ossia leggendo tutti i record che lo precedono partendo dal primo. Per quanto riguarda l’inserimento di un nuovo record (SCRITTURA), invece, l’organizzazione sequenziale prevede possa avvenire solo o in aggiunta (in APPEND), cioè accodando il nuovo record a quelli già presenti nel file, o in RISCRITTURA, cioè scrivendolo in prima posizione con la perdita di tutti quelli già presenti.
L’organizzazione sequenziale si dimostra indicata essenzialmente in quei casi in cui i record dell’archivio debbano essere utilizzati frequentemente nello stesso ordine in cui sono inseriti nell’archivio, in quei casi cioè in cui si debba fare per l’appunto un’elaborazione sequenziale dei record. Può essere questo il caso, per esempio, dei file di testo che possono essere pensati come un flusso di caratteri (byte stream) in cui la fine di ciascun record, ossia una riga di testo (che si fa notare è a lunghezza variabile), è segnalata al File System con un’opportuna sequenza di caratteri (per esempio CR + LF, nel caso dei sistemi Windows). L’organizzazione sequenziale, così come avviene nel caso di un file di testo, presenta il vantaggio di rendere possibile l’uso di record a lunghezza variabile, per contro però permette di disporre solo di un metodo di accesso sequenziale ai record. Essa pertanto è svantaggiosa con le applicazioni in cui sia fondamentale rendere minimi i tempi di risposta e, quindi, per questa sua inefficienza in generale non è adatta per applicazioni di tipo interattivo (applicazioni online).
Organizzazione ad accesso diretto
Quella ad accesso diretto è un tipo di organizzazione in cui ciascun record viene identificato dalla posizione occupata all’interno della sequenza di record del file di archivio. Si tenga presente che il primo record della sequenza ha posizione uno, il secondo posizione due e così via. Questo tipo di organizzazione prevede la possibilità di accedere in lettura/scrittura su un record direttamente, specificando la sua posizione. Questo tipo di organizzazione viene detta anche random, proprio perché permette di accedere direttamente ad un record senza la necessità di leggere tutti quelli che lo precedono, o anche relativa, in quanto il riferimento ad un record a cui si deve avere accesso è dato relativamente alla posizione da esso occupata nel file.
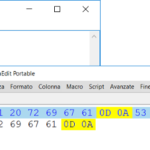
Si faccia attenzione, però, al fatto che l’organizzazione ad accesso diretto richiede necessariamente l’uso di record a lunghezza fissa (o costante), cioè aventi tutti la stessa dimensione in byte. Questo perché altrimenti verrebbe meno il meccanismo con cui a livello fisico il File System rende possibile accedere direttamente ad un record del quale si conosce la posizione. Se nel file di archivio i record hanno tutti la stessa lunghezza, infatti, il File System può posizionare il puntatore interno al file su un record che occupa un certa posizione, N, facendo un calcolo semplicissimo, ossia moltiplicando il numero di record che lo precedono, N-1, per la lunghezza fissata dei record, L, e aggiungendo 1 per portare il puntatore sul primo byte del record N a cui si vuole avere accesso:
(N-1) * L + 1 = indirizzo fisico del record di posizione N
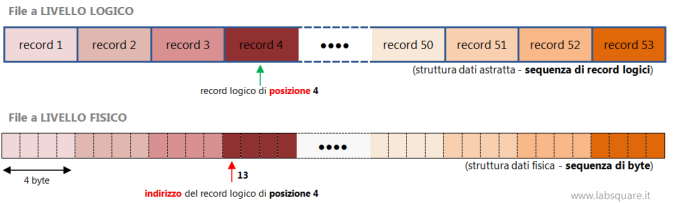
(4 -1) * 4 + 1 = 13
Questo tipo di organizzazione si presta bene in quei casi in cui i record dell’archivio vengono identificati utilizzando un numero d’ordine progressivo rispetto al quale devono essere mantenuti ordinati nell’archivio. Un esempio potrebbe essere quello dell’elenco degli studenti di una classe. Sfortunatamente questo caso non è molto frequente e nella maggior parte dei casi, invece, viene richiesto di avere la possibilità di effettuare un accesso associativo, ossia poter accedere ad un record in base ad una specifica informazione presente nello stesso record (un valore di uno o più campi). In questi casi allora è necessario ricorrere ad altre soluzioni che prevedono l’utilizzo di chiavi.
Organizzazione ad indici (indexed sequential)
L’organizzazione ad indici permette di realizzare un accesso associativo ai record di un archivio e il suo funzionamento si fonda sull’uso della chiave primaria.
Una chiave primaria (PK -Primary Key) è un campo o un insieme di campi del tracciato record che individuano in maniera univoca ciascun record di un archivio. Esempi di chiave primaria sono il codice fiscale, perché ciascun cittadino ha il suo codice fiscale che è diverso da quello di chiunque altro, oppure, per la stessa ragione, la partita IVA nel caso delle aziende. Si fa notare che per definizione di chiave primaria, in un archivio il campo della chiave primaria non può ammettere valori duplicati, il che vuol dire che nella tabella che rappresenta l’archivio, ciascun valore della colonna della chiave primaria può comparire una sola volta. Pertanto in quei casi in cui nel tracciato record non si riesce a trovare un campo o un insieme di campi che riescano a fungere da chiave primaria, si può ricorrere a una chiave ad hoc ossia si può aggiungere un campo che funga da codice identificativo con le caratteristiche enunciate sopra. Alcuni esempi possono essere il codice di un articolo, il codice di un cliente o la matricola di un dipendente.
Prima di passare ad illustrare l’organizzazione ad indici, discutiamo un semplice esempio che ci aiuterà a capire e ad apprezzare meglio i vantaggi di questo tipo di organizzazione. Si consideri la figura seguente (caso 1).
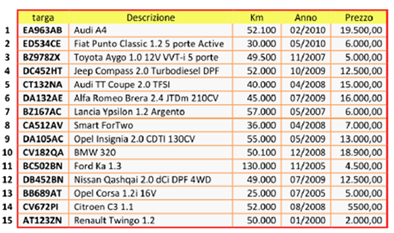
Si tratta di un archivio per la registrazione delle auto usate di una concessionaria. Esso presenta un campo di chiave primaria, targa, e viene gestito secondo un’organizzazione sequenziale. I nuovi record, infatti, vengono inseriti in coda a quelli già esistenti e mantenuti nell’archivio secondo l’ordine di inserimento. Esso, inoltre, non mette a disposizione alcun metodo per reperire la posizione occupata nell’archivio da un record di cui si conosce la targa. L’unico modo per accedere al record di un’auto con una targa specifica, consiste nel fare una scansione dell’archivio partendo dal primo record (ricerca sequenziale). Questo tipo di soluzione non è affatto efficiente, soprattutto quando il numero di record comincia a crescere.
Se si volessero migliorare le prestazioni dell’operazione di ricerca di un record, si potrebbe pensare di passare ad un’altra soluzione che, invece, prevede di mantenere l’archivio ordinato rispetto al campo PK della targa (caso 2).
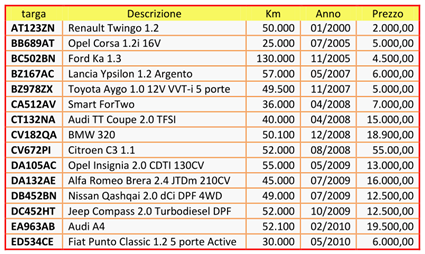
In questo modo si potrebbe utilizzare la ricerca binaria, che è sicuramente più efficiente di quella sequenziale. Rispetto a prima l’operazione di ricerca è diventata più efficiente, anche se l’operazione di inserimento è diventata più complessa e meno efficiente, dovendo mantenere l’archivio ordinato. Anche con questa organizzazione, man mano che il numero di record aumenta le prestazioni tendono a peggiorare e ad un certo punto potrebbero non essere più soddisfacenti.
Un’altra soluzione che rispetto alle precedenti potrebbe determinare un aumento delle prestazioni dell’archivio è l’organizzazione ad indice (indexed sequential).
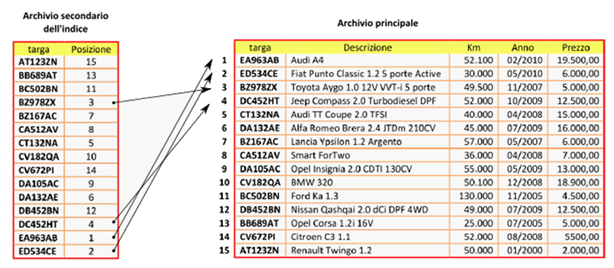
Oltre all’archivio principale, essa prevede anche l’utilizzo di un archivio secondario chiamato file indice. Quest’ultimo contiene due soli campi, quello delle chiavi primarie e quello dei puntatori ai record dell’archivio principale (ossia le posizioni occupate in esso dai record). Nel file indice sono presenti tutte le chiavi primarie dell’archivio principale (indicizzazione completa) e in corrispondenza di ciascuna chiave, il valore del puntatore rappresenta la posizione occupata nell’archivio principale dal record corrispondente a quella chiave. Il file indice deve essere memorizzato in un file ad accesso diretto e deve essere ordinato rispetto alle chiavi, in modo da permettere la ricerca binaria. Nell’archivio principale, invece, i nuovi record vengono inseriti solo in coda e mantenuti nello stesso ordine in cui sono inseriti; esso inoltre deve essere memorizzato in un file che dispone dell’accesso diretto, in modo da consentire di posizionarsi direttamente sul record che occupa la posizione trovata nel file indice.
L’inserimento di un nuovo record in un archivio di questo tipo comporta:
- L’inserimento del record vero e proprio in coda all’archivio principale.
- L’aggiornamento del file indice: l’inserimento di un nuovo record contenente il nuovo valore di chiave primaria e la posizione del record aggiunto nell’archivio principale. Si ricorda che l’archivio secondario dell’indice deve essere mantenuto ordinato rispetto alla chiave primaria.
L’accesso ad un record con un certo valore della chiave primaria, invece, comporta:
- La ricerca (preferibilmente binaria) della chiave primaria all’interno del file indice e la lettura del valore della posizione corrispondente.
- L’accesso diretto al record nell’archivio principale che si trova nella posizione trovata.
Poiché il file indice e l’archivio principale hanno lo stesso numero di record, si potrebbe obiettare che con l’organizzazione ad indice rispetto alla seconda soluzione vista prima (il caso 2, ossia quella che prevedeva un unico archivio con l’aggiunta del campo di chiave primaria, mantenendo l’archivio ordinato), le prestazioni non solo non dovrebbero migliorare, ma addirittura peggiorare. Infatti, le procedure algoritmiche necessarie per realizzare le operazioni di inserimento ed accesso ad un record, sono rimaste sostanzialmente le stesse con l’aggiunta di ulteriori operazioni che derivano dal dover gestire due tabelle invece di una sola: nel caso dell’inserimento di un nuovo record, si aggiunge il passo a), nel caso dell’accesso ad un record, il passo 2). Invece non è così! Con l’organizzazione ad indice, infatti, il miglioramento delle prestazioni delle operazioni di ricerca e di ordinamento è dovuto al fatto che il tracciato record del file indice è composto da due soli campi, mentre quello dell’archivio principale è composto da molti campi. Per questo motivo poco importa che il file indice contiene lo stesso numero di record di quello principale e che, quindi, il numero di record da ordinare e tra i quali ricercare la chiave è identico. Ciò che fa la differenza e che garantisce una maggiore efficienza delle operazioni eseguite sul file indice è che esso ha un fattore di blocco sicuramente maggiore rispetto all’archivio principale. Questo fatto sappiamo (link articolo) riduce il numero di accessi di I/O alla memoria di massa, che sono molto lenti, determinando così un incremento apprezzabile delle prestazioni dell’archivio.