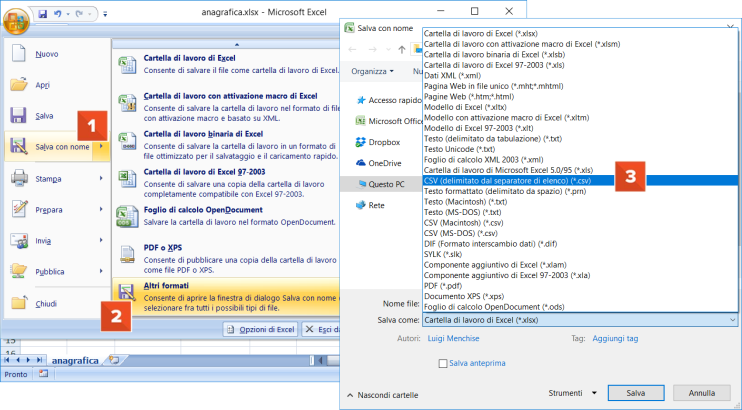
Nell’articolo in cui abbiamo introdotto i principali tipi di organizzazione degli archivi tradizionali (link articolo), abbiamo parlato di organizzazione sequenziale. Un esempio di file di archivio con questa organizzazione sono i file nel formato CSV, acronimo di Comma Separated Value, che letteralmente si traduce con “valori separati da virgola”. Si tratta di semplici file di testo (ASCII) che possono, quindi, essere aperti anche con un editor di testo come “Blocco note” di Windows. Per quanto le specifiche di questo tipo di file non risultino unificate in uno specifico standard, tuttavia costituisce uno dei formati più utilizzati per l’importazione e l’esportazione di dati in forma tabellare, ad esempio da fogli elettronici e dai gestori di database relazionali (RDBMS) e, quindi, per lo scambio di dati fra applicazioni di tipo diverso. Tale formato per esempio è supportato sia da Excel sia da Calc di OpenOffice, che permettono di esportare una tabella di un foglio di lavoro in questo formato e sono in grado di aprire i file in questo formato come fogli di lavoro. La figura di sotto mostra come esportare una tabella di Excel nel foramto CSV.
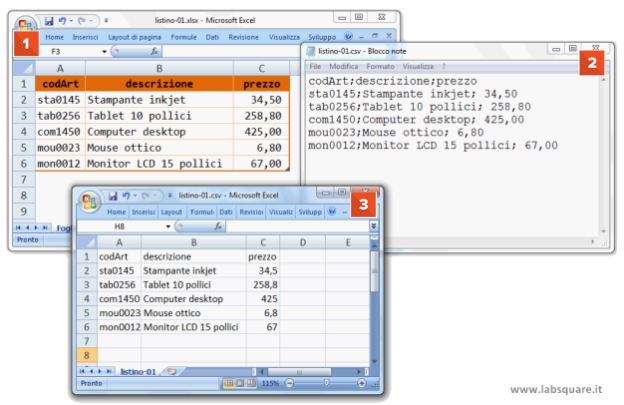
La figura di sotto mostra un semplice esempio di una tabella di un foglio di lavoro di Excel [1], che è stata salvata in un file nel formato CSV successivamente aperto sia con l’editor di testo di Windows [2], sia con Excel stesso [3]. Il file aperto nell’editor di testo evidenzia che nel formato CSV ottenuto da Excel, ogni riga di testo rappresenta un record della tabella. In ciascuna riga i valori dei campi sono separati tra loro con un punto e virgola, che funge da carattere speciale di fine campo, mentre il carattere di nuova riga funge da carattere speciale di fine record. Nel formato CSV, quindi, i dati sono organizzati come una sequenza di record logici a lunghezza variabile memorizzati nel formato ASCII (testo).
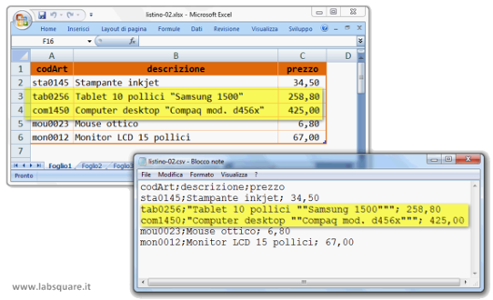
In generale, nel caso più semplice in cui per i campi del tracciato record della tabella di origine non siano ammessi valori che contengano i caratteri di nuova riga e il carattere speciale di fine campo, il formato CSV prevede che ogni riga di testo rappresenti una riga della tabella di origine e che, per separare i campi all’interno di ciascuna riga, venga utilizzato come carattere di fine campo una virgola, oppure un punto e virgola laddove la virgola venga usata come separatore delle cifre decimali (è questo il caso di Excel). Nel caso più generale, invece, in cui un campo del tracciato record possa contenere anche i caratteri di nuova riga e il carattere speciale di fine campo, quel campo viene racchiuso tra doppie virgolette. Se all’interno di un campo, inoltre, vengono utilizzate le doppie virgolette, quel campo viene racchiuso tra doppie virgolette e le doppie virgolette presenti nel campo vengono raddoppiate. Quest’ultimo caso viene mostrato nell’esempio della figura di sotto con le righe evidenziate in giallo.
Un altro formato molto utilizzato, alternativo al CSV, è il formato TSV, acronimo di Tab Separated Values che letteralmente può essere tradotto con “valori separati da tab”, ossia il carattere ASCII di codice 9 che corrisponde ad una tabulazione orizzontale. Per questo tipo di file valgono le cose già dette per i file di tipo CSV. Anche questo è un tipo di file sequenziale che consiste in un semplice file di testo in cui, però, questa volta come carattere speciale di fine campo viene utilizzato un carattere di tabulazione. Anche questo formato è riconosciuto dai fogli elettronici e dai gestori di database (RDBMS) ed è molto utilizzato per lo scambio di dati in formato tabellare fra applicazioni di tipo diverso. Le estensioni utilizzate per questo formato sono .tav o .tab, oltre che naturalmente .txt.