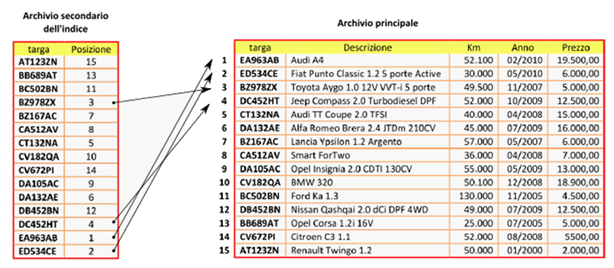
Che cosa s’intende per organizzazione indexed sequential di un archivio viene già spiegato in un articolo che introduce i principali tipi di organizzazione degli archivi tradizionali, a cui si rimanda (link). In questo articolo, invece, si propone un’esercitazione di laboratorio di approfondimento sui files con C++, in cui viene sviluppato proprio l’esempio di archivio a singolo indice di chiave primaria con indicizzazione completa di quell’articolo, mostrato anche nella figura seguente.
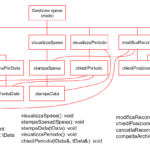
Descrizione del progetto
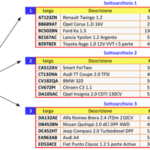
Si consideri l’archivio per la gestione delle auto di una concessionaria mostrato in figura e il cui funzionamento è spiegato in maniera dettagliata nell’articolo citato sopra, a cui si rimanda (link). Si richiede di sviluppare in C++ un programma che realizzi le seguenti funzionalità:
- Aggiunta di una nuova auto.
- Ricerca e visualizzazione dell’auto con la targa fornita in input
- Visualizzazione della tabella delle auto in ordine crescente di targa.
- Modifica di un’auto identificata dalla targa fornita in input.
- Cancellazione logica dell’auto identificata dalla targa fornita in input.
- Ripristino di un auto cancellata logicamente, identificata dalla targa fornita in input.
- Visualizzazione delle auto che risultano cancellate logicamente.
- Compattazione dell’archivio con cancellazione fisica delle auto cancellate logicamente.
Soluzione proposta
I dati del problema vengono organizzati nelle strutture seguenti:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
typedef char t_targa [10]; struct t_data { int giorno; int mese; int anno; }; struct t_auto { t_targa targa; char descrizione[30]; int km; t_data dataImm; float prezzo; bool cancellato = false; }; struct t_indice { t_targa targa; int posizione; }; |
Si ricorda che questo tipo di organizzazione richiede che i files dell’archivio principale e dell’indice dispongano di un accesso diretto ai record dei quali si conosce la posizione (posizionamento diretto), pertanto siamo obbligati ad utilizzare dei record a lunghezza fissa.
Applicando la metodologia top-down si può giungere alla seguente scomposizione funzionale.
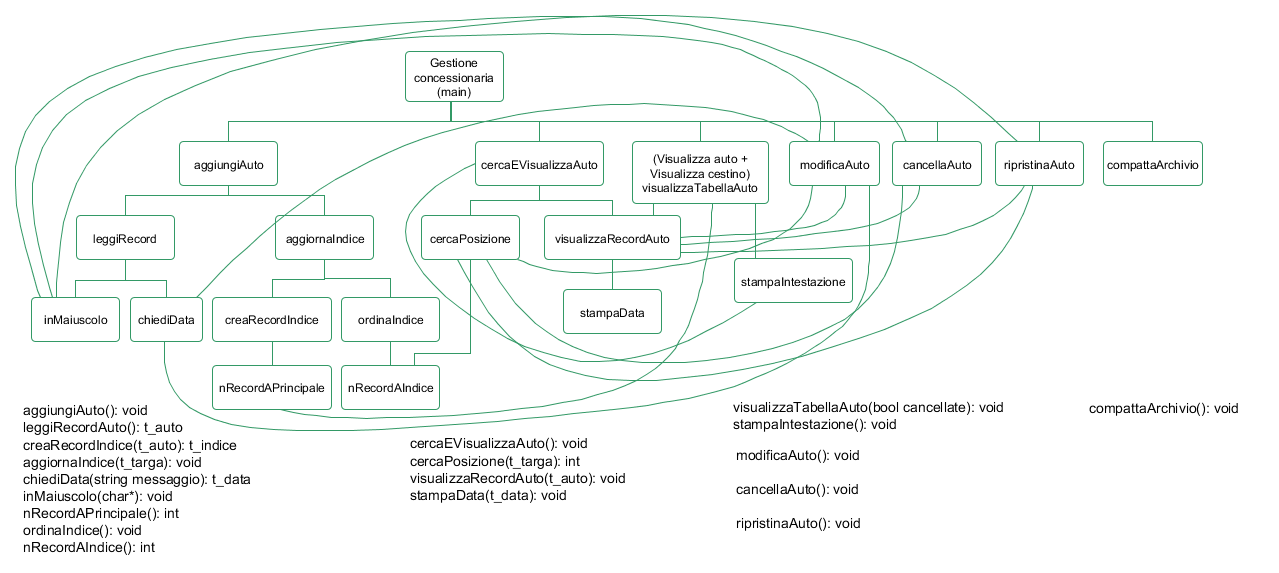
Seguono i link ai files sorgenti dell’intero progetto sviluppato in C++. Ciò che ciascuna delle funzioni individuate nella scomposizione funzionale dovrà fare, viene spiegato nei commenti inseriti nei files sorgenti allegati. Si fa notare che alcune di queste funzioni coincidono con quelle utilizzate in un altro progetto a cui si rimanda (link). Ciò è stato possibile perché anche in quel progetto si è operato utilizzando la metodologia top-down che, sappiamo, fra i vantaggi che apporta c’è appunto il fatto di favorire la riutilizzabilità del codice.
main.cpp myHeader.cpp myTipiDato.cpp myFunzioni.cppP.S. Nel codice C++ allegato la posizione dei record nei file dell’archivio è stata contata partendo da zero (il primo record ha posizione 0) e non da uno come mostrato nella prima figura di sopra.