Una chiave secondaria, o alternativa, è un campo del tracciato record che permette di individuare un sottoinsieme di record all’interno di un archivio. Si fa notare che la definizione stessa di chiave secondaria implica che in un archivio il campo di chiave secondaria ammette valori duplicati. Alcuni esempi di chiave secondaria possono essere: in un archivio dei clienti, il campo della provincia di residenza, per individuare tutti i clienti di una certa provincia; in un archivio di prodotti, il campo della categoria, per individuare tutti i prodotti appartenenti ad una certa categoria, ecc.
In generale si ha che se un archivio è organizzato solo rispetto alla sua chiave primaria (ad esempio è ordinato rispetto al campo della chiave primaria oppure è organizzato con un file indice delle chiavi primarie, link articolo) e nel tracciato record è presente un campo che deve funzionare da chiave secondaria, perché capita spesso che debbano essere effettuate operazioni di ricerca di sottoinsiemi di record (operazione di selezione) a partire da un certo valore di quel campo, l’unico modo per ritrovarli è quello di realizzare una scansione completa dell’archivio principale alla ricerca di tutti quei record che soddisfano tale condizione (ricerca sequenziale). Una soluzione di questo tipo è poco efficiente ed è inaccettabile nel caso di archivi con un elevato numero di record, a causa degli elevati tempi di risposta che comporterebbe. Per migliorare l’efficienza di una tale operazione di ricerca, può essere opportuno ricorrere ad una diversa organizzazione dell’archivio. Una di queste può consistere nel utilizzare un indice di chiave secondaria come mostrato nell’esempio della figura seguente.
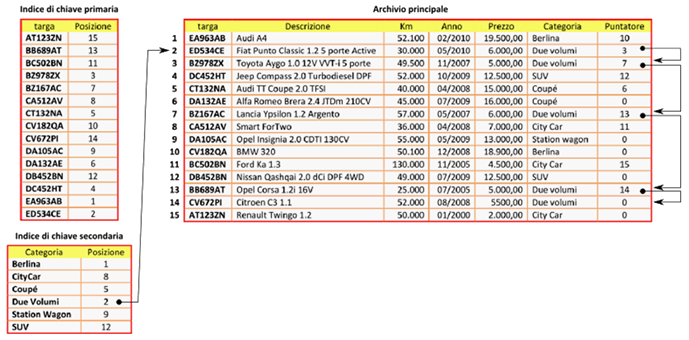
La figura riprende l’esempio dell’archivio a singolo file indice con indicizzazione completa che abbiamo già incontrato in un articolo precedente (link articolo). In esso l’archivio principale è organizzato come una struttura sequenziale non ordinata in cui i record vengono inseriti solo in coda e nel quale, però, adesso oltre al file indice delle chiavi primarie, è presente anche un file indice delle chiave secondarie. Nel tracciato record dell’archivio principale, inoltre, è stato aggiunto un campo di chiave secondaria, “Categoria”, e un campo puntatore, “Puntatore”, quest’ultimo destinato a contenere la posizione di un altro record dell’archivio principale, secondo la logica illustrata sotto.
Il file indice di chiave secondaria ha un tracciato record composto da due campi:
- quello delle chiavi secondarie (nell’esempio il campo “Categoria”);
- l’altro cosiddetto puntatore, che contiene la posizione dell’archivio principale in cui viene inserito il primo record che ha il corrispondente valore di chiave secondaria.
Nel caso particolare dell’esempio in figura, nel file di chiave secondaria il record con chiave “Berlina”, punta al record di posizione n. 1 dell’archivio principale perché esso risulta essere il primo con quel valore di chiave secondaria; quello con chiave “Citycar” punta al record di posizione n. 8 perché esso risulta essere il primo con quel valore di chiave secondaria “Citycar”, e così via.
In definitiva, questo tipo di organizzazione prevede che ciascun record del file indice di chiave secondaria, punti al primo record inserito nell’archivio principale che ha il suo stesso valore di chiave secondaria. Nell’archivio principale, invece, ciascun record punta al primo record con lo stesso valore di chiave secondaria che lo segue, a meno che non si tratti proprio del primo e ancora unico o dell’ultimo record inseriti con quello specifico valore di chiave. In tal caso per essi, non avendo alcun record successore, il campo puntatore non può contenere alcun valore di posizione (posizione zero). In questo modo, quindi, potremmo dire che nell’archivio principale il campo puntatore viene utilizzato per creare una sorta di “catena di puntatori” che collega fra loro tutti i record che hanno lo stesso valore di chiave secondaria; la posizione del primo record di questa “catena” può essere recuperata consultando l’indice di chiave secondaria.
Per velocizzare l’operazione di ricerca di una chiave secondaria, l’archivio dell’indice deve essere ordinato rispetto al campo delle chiavi secondarie in modo da poter eseguire una ricerca binaria e, per rendere più semplice la stessa operazione di ordinamento, è opportuno che esso venga realizzato con un file ad accesso diretto. Si noti che nell’indice di chiave secondaria, ciascun valore di chiave secondaria deve comparire una volta sola.
Con questo tipo di organizzazione, per eseguire un’operazione di selezione, ossia di ricerca di tutti i record con un certo valore della chiave secondaria, basterà:
- consultare l’indice di chiave secondaria, alla ricerca del valore di chiave secondaria fissato: in questo modo si recupera la posizione del primo record della “catena” dei record con quel valore di chiave secondaria;
- leggere tutti i record dell’archivio principale con quel valore di chiave secondaria, dal primo record fino all’ultimo, seguendo la “catena” dei puntatori.
Le altre operazioni logiche sull’archivio, però, diventano più complesse. Ad esempio, per l’operazione di inserimento di un nuovo record, oltre all’inserimento in coda del record nell’archivio principale e all’aggiornamento dell’indice di chiave primaria, che avviene come già discusso nell’articolo precedente (link articolo), bisognerà:
- aggiornare l’indice di chiave secondaria, solo nel caso in cui si tratta del primo record inserito con quel valore di chiave secondaria;
- aggiornare il campo puntatore dell’ultimo record che è stato inserito nell’archivio principale con quel valore di chiave secondaria, solo nel caso in cui non si tratta del primo inserimento di un record con quel valore di chiave secondaria.
Un indice di chiave secondaria, quindi, riesce a migliorare le prestazioni di selezione di sottoinsiemi di record di un archivio, individuati da un stesso valore della chiave secondaria. Ovviamente ciò avviene a discapito di una maggiore complessità di gestione dell’archivio che si sottolinea, in questo tipo di archivi detti tradizionali, è tutta a carico del programmatore.
Concludiamo quest’articolo con una brevissima parentesi. In un archivio organizzato su più file le chiavi secondarie possono essere utilizzate anche per mantenere le correlazioni fra i record di tabelle diverse (alle correlazioni tra i dati di tabelle diverse di un archivio si è accennato in un articolo precedente: link articolo). Quando si hanno due tabelle di dati correlati, infatti, un valore di una chiave secondaria può essere utile per individuare un sottoinsieme di record di una prima tabella, che sono correlati ad un record di una seconda tabella che ha come valore di chiave primaria proprio quello considerato per la chiave secondaria della prima tabella. In questo caso particolare, che approfondiremo quando parleremo di database e DBMS, la chiave secondaria viene detta chiave esterna.